The spectre of a Facebook phone is upon us. A new phone that won’t be tied to hardware; a phone that is simply collection of interconnected apps that combined serve the basic function of a phone. A phone created by Facebook, but hardware independent; like a spectre, the physical shape will differ depending on the encounter. This experience has been purchased piece by piece for billions of dollars, as much a phone without a phone as a Frankenstein monster made from mergers and acqui-hires that lays waiting on the operating table for lightning to strike. All that’s missing is a lighting bolt – the user interface – to energize these pieces into the experience of a phone, a phone by Facebook.
The Downloads folder is pretty much a standard feature on any modern OS. I remember my first experience with it was on Mac OSX Tiger (10.4). It became a very handy and frequently visited folder; before I was just saving all my downloads to the desktop for easy access.
Now that every browser defaults to saving files in the downloads folder(as they should), I find my downloads folder getting way to cluttered. After a few weeks, I end up with a folder filled with hundreds of files (and folders from unzipping applications), and it becomes a pain to find the file you just downloaded. Plus the folder looks very cluttered when you open it.
Being a pack-rat, I rarely delete things from my Downloads folder. I probably should, but instead I wrote a simple bash script, tied to a chron job, that will re-organize my Downloads folder and give me a fresh “empty” one each day. I call it Empty Downloads.
Update: Dwolla contacted me soon after this post and put out an update to this issue the next week. Shout out to Dwolla!
I’ve been using Dwolla for the past few months to pay rent on my co-working space and I feel I need a space to vent my frustrations. If their transaction fee wasn’t so low (25 cents), I would switch to a more familiar payment processor since their user experience is so poor.
Dwolla’s central promise of being able to send money to anyone, anywhere is appealing. However, the execution is a little bit off. Often times, I don’t need to send money to anyone, anywhere. I just need to send money to a select group of people.
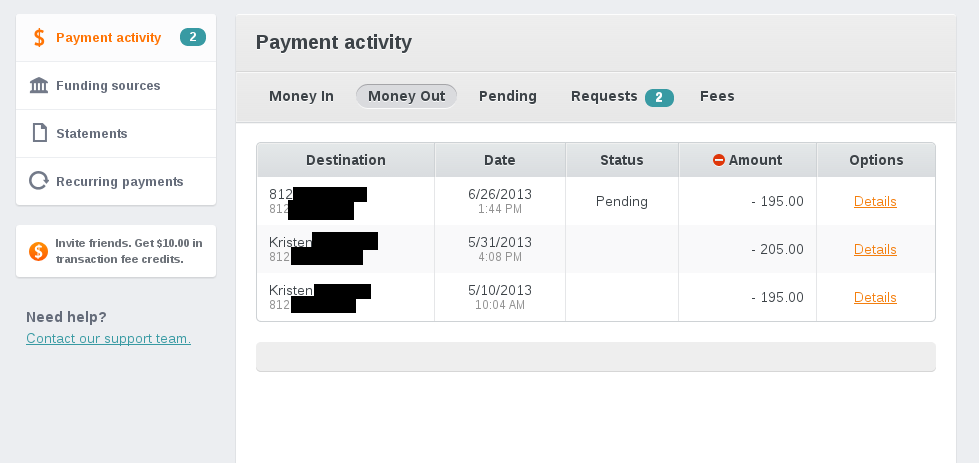
Here is a screenshot of my Dwolla transaction history, showing payments made for my co-working space.
What’s wrong with this picture?
The phone numbers are all the same, but for some reason Dwolla doesn’t recognize that the 812 number belongs to Kristen (to whom I pay my rent). This is unnerving since Dwolla can’t seem to keep track of people’s names and associated phone numbers, I have no idea if they payment went out or not. Dwolla has already lost my trust by missing this important part of user experience, so I don’t have faith the rest of the service works. (Spoiler alert: it doesn’t; we’re still trying to sort out how payments work on this thing)
Why do the other payments show Kristen’s name and not this most recent one? I have no idea.
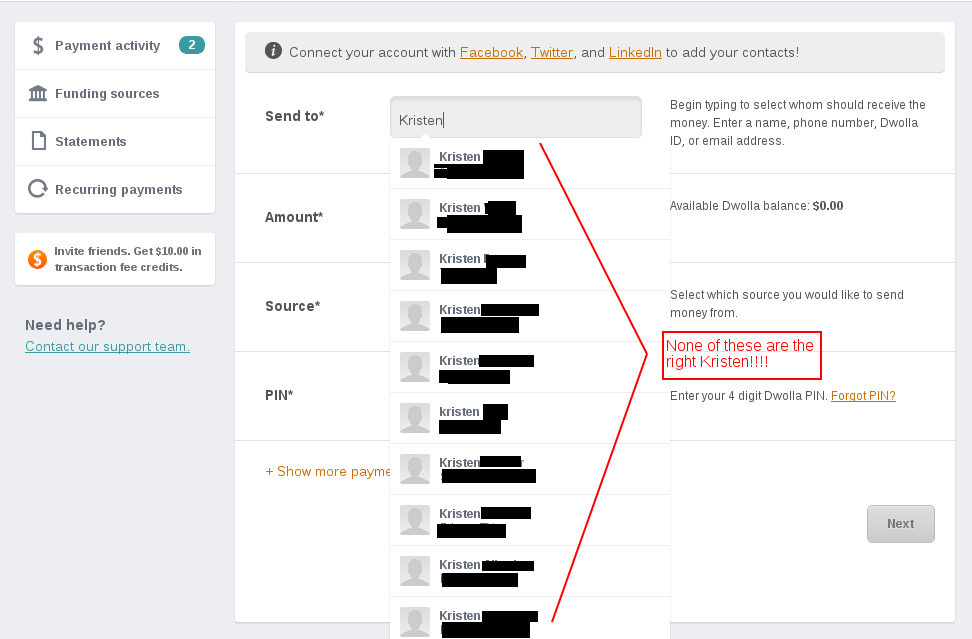
Even more unnerving is the drop-down menu when you go to pay someone.
As mentioned in the image, none of these are the right Kristen! It seems logical that the most recent people I paid would float to the top of the autocomplete list, or at least be in the list at all, but I guess it’s more important for Dwolla to show me random users that are also named Kristen in the off-chance I want to send them $200 for rent in the co-working space.
So here are my requests for a better Dwolla user experience:
Link together names and phone numbers. When you don’t, I am greatly worried that I am sending money to random people because I typed a phone number one digit off.
Maintain a list of people I have recently sent money to so I can easily send them money again.
Have people I’ve recently sent money to float to the top of the autocomplete, or at least have them exist in the autocomplete.
So now it’s July 2nd, the money sent to Kristen’s phone number has still not arrived (nor has it shown up in her payment history). We’re now trying to see if Dwolla will recognize the e-mail address associated with Kristen’s account.
Thanks Dwolla, for not providing an easy way for me to send money to people I have sent money to previously and for making your user interface terrifying by not linking up names and phone numbers/Dwolla IDs.
Update: Dwolla contacted me soon after this post and put out an update to this issue the next week. Shout out to Dwolla!
Over the past few months, one of my favorite tools has become CasperJS, which is a navigation and testing utility than runs on top of PhantomJS, a headless web browser. This is a great tool for doing web scraping, which you can use to automate the retrieval of data from webpages, among other things. Sometimes though, you want to test a target web page from a variety of different IP addresses, or find yourself behind a block of banned IP addresses, or just need to anonymize your activity. This is where Tor comes in handy.
Web scraping is a lot of fun, but make sure you are following the commonly accepted rules of web scraping:
Make sure you’re following the target site’s Terms of Service. This means respecting robots.txt and any other restrictions there may be.
Limit your requests. Scraping bots can navigate webpages much faster than normal humans, and you don’t want to accidentally DOS a site with an out of control scraper.
Be nice to the server. If you don’t need images, modify your scraper so it doesn’t download images (PhantomJS has a --load-images=false flag for this). If you want to be really nice to the server, put your e-mail address in the scraper’s HTTP headers so the server admin can contact you if your scraper is giving them a problem.
(These rules were partially adapted from this list)
Now, on to how to “Tor-ify” CasperJS.
Download Tor
Well, obvs. I normally use REHL-based Linux distros, so I’m going to link to those instructions. Once torproject.repo is in your /etc/yum.d or /etc/yum.repos.d, you should be able to yum install tor with no problem. Then start the service with service tor start.
After you’ve confirmed that Tor can run on your machine, feel free to shut it down, as we’ll be coming back to that later.
Write a Script for Testing
How will you be able to tell that CasperJS is properly proxying through Tor? Why not write a script that scrapes whatismyip.com?
Taking a look at the source of whatismyip.com, it looks pretty simple to scrape. The IP address is contained in a div that has a handy id that we can pull data from. My workflow for writing scripts with CasperJS is to fire up the target webpage, write some code in Chrome Developer Tools, then copy that code back into my CasperJS script. Taking a look at the source for whatismyip.com, we can use some vanilla javascript to grab the IP address.
1
var ip = document.getElementById('greenip').textContent.trim()
As a force of habit, I normally add .trim() on to the end of any text I pull out of a DOM node since there’s no point in keeping useless whitespace.
Now, let’s star writing our CasperJS script.
12345
var document=[]
var casper=require('casper').create({
verbose: true,
logLevel: "info"
});
I like to keep logging on for most of my Casper scripts, just because it’s helpful to see what’s going on and the output looks cool. Now we’ll define the first step of our scraping process:
This simply tells CasperJS to use PhantomJS to load up http://whatismyip.com.
An important note about CasperJS is even though everything is written in Javascript, you can’t actually manipulate or read the page you’ve loaded into CasperJS without running the evaluate function. So we’ll add to our first step:
Once you’re inside this.evaluate, you have access to the document object. Also, notice how we do output with console.log, instead of this.echo. This is because once inside the evaluate function, you no longer have access to the this that refers to the Casper object.
Ok, so tying everything together for this really complicated script:
You always have to put casper.run() at the end of your scripts to kick of the process of running through the steps. Now, if you’ll watch your terminal output, you should see your IP address output in the [info] [remote] section of the output. Yay!
Now, start up Tor again and we’ll pass in some parameters and see if the IP address changes.
Proxy PhantomJS
Tor is a SOCKS proxy, not an HTTP proxy. (Most of my previous exposure to Tor was through the Tor Browser Bundle, so this was interesting to me). But PhantomJS can also run through a SOCKS proxy, so no worries. Add these parameters when you start the script:
--proxy-address=127.0.0.1:9050--proxy-type=socks5
(If you Tor proxy isn’t running on 127.0.0.1:9050, you should change that parameter. You’ll see where the Tor proxy is running when you run service tor start.)
So, running my final Tor-ified CasperJS setup looks a little like this:
Note: while using Tor requests can take significantly longer to go through. I’ve seen some requests with this script take as long as 114 seconds to resolve, but such is the nature of Tor.
Won’t you do the world a favor and add a relay to the Tor network?
I’m writing this post because I’ve been using Drupal to rapidly-prototype an MVP (and I have many, many thoughts on Drupal, but I won’t get into them here). One of the features was to have a list of followers (who follow a user) and a list of the users that a certain users follows, which is a very typical setup. I’m writing this post because I had one hell of a time putting this thing together in Drupal 7, and I’m hoping it will save someone else from going through the pain I went through.
First, let’s rubber duck and clearly define our requirements for the two lists.
Following: A list of users that a specific user has flagged ‘follow’. In other words, a list of users flagged by another user.
Followers: A list of the users that have flagged a specific user to ‘follow’. In other words, a list of users that have flagged another user.
I’m using the terminology flag here since we’ll be using the flag module to put together the following/followers functionality. The two modules we’ll need are:
First, you’re going to need to create a new flag for ‘follow’. Setting up a new flag is fairly trivial, and I called my flag ‘follow_user’ and set it to be a global flag.
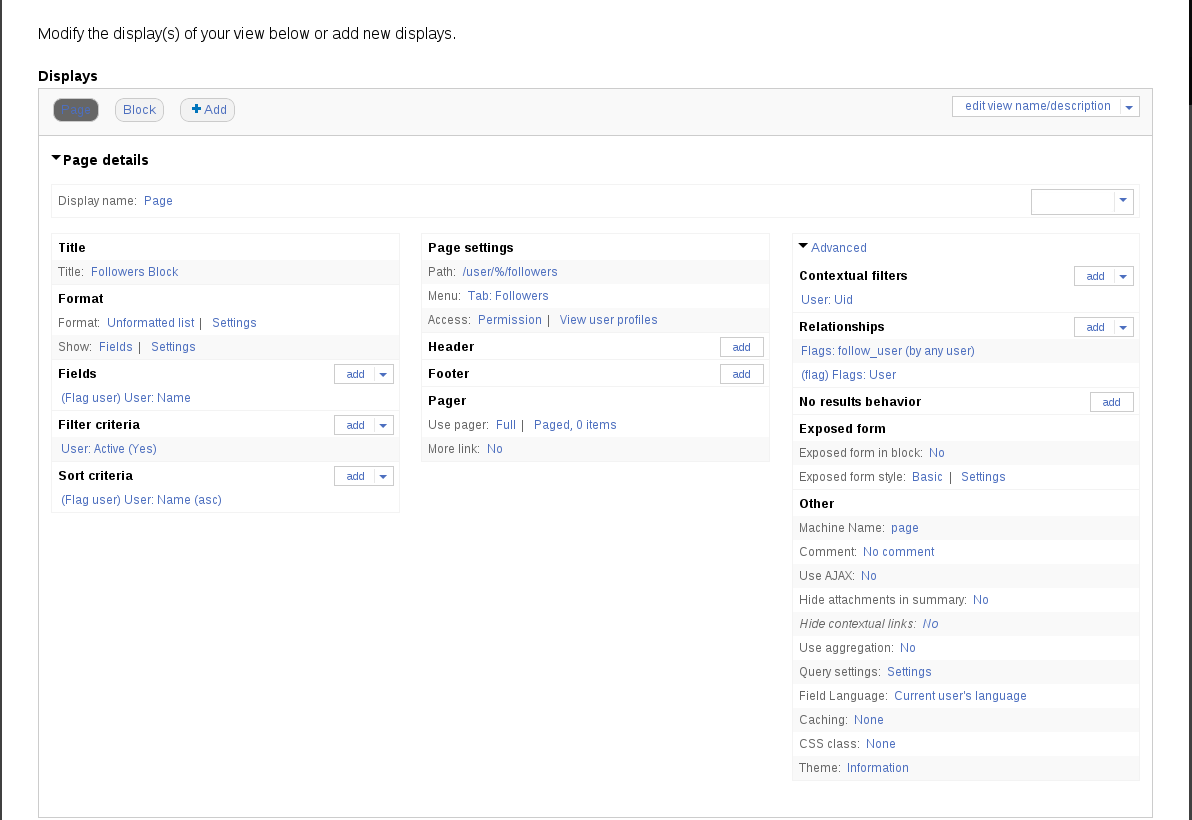
Now, create a new view for Followers. You’re going to need to set the following options:
Title (very important, but just for you)
Path: /user/%/followers (or anything you’d like, as long as the % is in there)
Contextual Filter: User(uid) (this is to grab the uid out of the % in the path)
Set the Contextual Filter above to ‘do not use a relationship’. This step is important
Create a ‘Flags: User Flag’ relationship for any user (not just the current user)
Create a ‘Flag: User’ relationship to grab the user data from the above relationship. (the relationship drop down should reference the flag created in the step above)
Create a ‘User:Name’ field that uses the above relationship
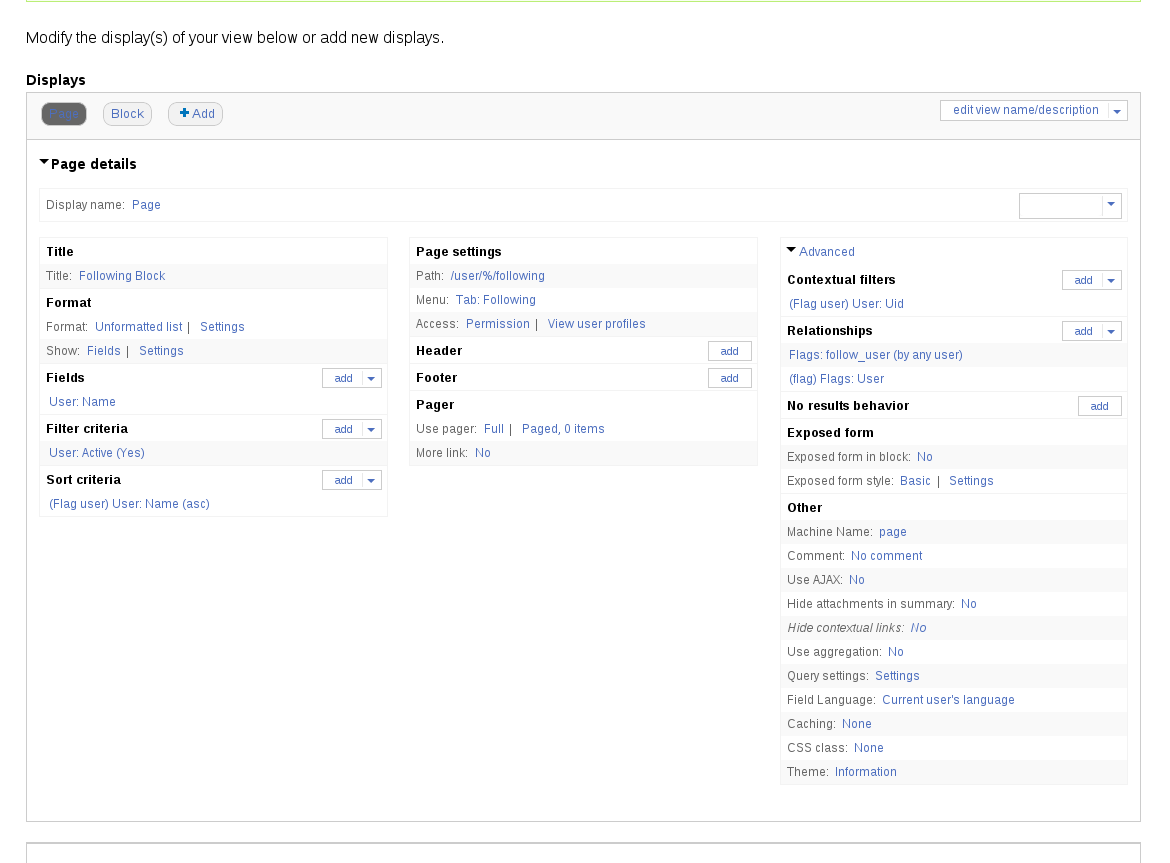
And that’s how you do the followers tab. For the following tab, create another view, with basically the same parameters (the path and will be different, obvs), but the major differenct is with the Contextual Filter:
Make sure the contextual filter is referencing the Flag User relationship (you may need to set up the relationships first, then add the Contextual Filter).
Also make sure that the ‘User:Name’ field does not reference the relationshp (or else it will just repeat the name of the current user you are viewing).
For reference sake, here is what the views look like in my admin:
Facebook is making changes to its Data Use Policy and Terms of Service (Statement of Rights and Responsibilities). Per the current policies, these changes have to be put up to a vote by Facebook users. Of course, the vote is only valid if 30% of the user base participates in the voting (that’s about 300 million people). At the time of this writing, only about 16 thousand users have voted and a majority of those (90%) have voted against the new policies.
In addition to minor changes clarifying data collection, privacy settings, and affiliates, the major change that comes with the new policies is the abolition of voting itself. If the new policies are passed, then there will be no more voting on new policies. Instead, there will be a seven day comment period before they are put in place.
Given the virality of the fake Facebook copyright notice, I’m surprised that the voter turnout is so low. On the other hand, Facebook has not done much in terms of publicising this effort. I suspect they want to do away with voting altogether, as it has never had a meaningful impact on the site’s policies and operations.
In lieu of a document comparing the two policies (other than this pdf from Facebook), I’ve created a little voters guide.
Here are the upcoming Facebook policy changes:
Data Use Policy
Signing up
Old Policy
New Policy
Required to provide name, email, birthday, and gender.
Have to provide information such as that in the old policy, but may use a telephone number.
Information received by Facebook
Old Policy
New Policy
Does not mention Facebook’s affiliates.
Language modified to include Facebook’s affiliates(see note)
Note on Affiliates
Facebook defines affiliates to be business that are legally part of the same group Facebook is a part of. I take this to mean Facebook Ireland, which is a company set up to take advantage of Ireland’s tax laws, and Facebook Hypderabad.
Messaging (@facebook.com email address)
Old Policy
New Policy
Contained details on how to control who messages you.
Now anyone in a conversation can message you.
How Facebook uses your information New Policy:
Insertion of a clause – “in addition to helping people see and find things that you do and share” – prefacing examples of how Facebook uses your information.
Timeline
New Policy: A reminder that even though you may hide a post, people may see it elsewhere, like on someone else’s timeline or search results.
Finding you on Facebook
Old Policy
New Policy
Only friends will be able to find you via e-mail address or phone number, depending on your privacy settings
People will be able to find you though a post to a public page or if you are tagged in a friend’s post or photo
Personalized Ads New Policy: Clarifies how personalized ads work.
Sponsored Stores New Policy: Subscribers, in addition to friends, will see sponsored stories.
Data Retention New Policy: Facebook may retain information from suspended accounts for up to a year to detect repeat offenders.
Invitations
Old Policy
New Policy
Facebook will send up to two reminders to friends you invite.
Facebook will send a few reminders to friends you invite.
Affiliates New Policy: Facebook may share information about affiliates (see note above).
Opportunity to Comment and Vote New Policy: Voting is removed, as is the 7000 comment threshold for triggering a vote. Now users have seven days to comment before a change goes into effect.
Statement of Rights and Responsibilities
Your Facebook Timeline
Old Policy
New Policy
You will not use a personal Facebook account primarily for commercial gain.
You will not use a personal Facebook account primarily for commercial gain, and will create a Facebook Page to do so.
Promotions from Pages New Policy: If you run a promotion on your timeline from your page, you agree to the Pages Terms of Service.
Amendments to the Policy New Policy: Voting removed as well as the 7000 comment threshold (similar to the changes to the Data Use Policy). Seven day comment rule also applies here.
This week I’m deep in the process of converting a variety of PHP/MySQL backed sites (mostly Joomla and Symfony 1.4) over to Octopress, mostly because I don’t want to deal with the overhead of running MySQL (In the past, I’ve had to upgrade my Slicehost VPS in order to keep MySQL from hanging). Some of the pages had a little Facebook likebox included with them to collect likes.
My search for an Octopress aside that would create a likebox was fruitless, so I made one.
How it works
Basically there is a plugin (likebox.rb) and an aside (likebox.html). To use the plugin/aside you move the files into their respective correct locations, then modify the default layout to load the likebox.rb plugin if Facebook likebox configuration is detected in _config.yml. The only reason there is a plugin is to load up the Facebook Javascript SDK code so the markup in likebox.html works correctly.
I’m wondering if there is a more elegant way to load up the Javascript SDK rather than just adding an if loop that will spit out static markup if true.
It’s a simple plugin that generates some interesting markup for embedding videos (you essentially embed the raw source into an iframe and hope the server on the other end will serve up a player with the html5 or flash stream).
The size of the player/viewport is controlled CSS that defines a responsive, intrinsic ratio for the video.
Deanna’s mother takes Worf’s son to a skitzoid paradise and explains to him that he is only a body filled with organs. Meanwhile, the space parasites that were eating the ship are ejected into an asteroid belt, and the Enterprise becomes a body without organs.
Picard betrays his surrogate father, then discovers the meaning of life, but the search overextends the propulsion system and the ship has to be repaired for two days.